
Contents
- Introduction
- Background
- Advancements in AngleSharp
- Connecting Jint
- Using the code
- Points of Interest
- History
Introduction
More than a year ago I announced the AngleSharp project, which is quite ambitious. The project tries to implement the specification provided by the W3C and the WHATWG regarding HTML/CSS. In its core we find a state-of-the-art HTML(5) parser and a capable CSS(3) parser, which contains L4 modules, such as CSS4 Selectors.
Since its announcement the project has been quite a success. AngleSharp has been released in form of a portable class library (PCL). This enables the usage on .NET 4.5+, WindowsPhone 8+ and Windows Store applications. In general the tendency to use lightweight portable solutions is still rising, which explains the ongoing demand and questions regarding the project.
Even though AngleSharp started as a tool for parsing HTML, it is much more. AngleSharp provides several points for extensions and can not only be used to parse HTML in order to create a DOM as specified by the W3C, it knows about scripting and styling. AngleSharp itself does not contain a scripting engine out-of-the-box, but it provides a default styling engine that knows CSS. Part of the reason is the strong connection between HTML and CSS. As an example the querySelector() and querySelectorAll() API methods use a string as argument, which is interpreted by the CSS engine.
This article will discuss some of the current extension points. We will also have a look at upcoming extension points - just to illustrate the roadmap and vision for AngleSharp. Finally the whole extension point topic will be motivated by showing how an existing JavaScript engine can be connected to AngleSharp. We will see that the whole process is more or less straight forward, does not require much code and results in interesting applications.
Background
JavaScript is not the only language that can be used for writing web applications. In fact, Microsoft provided VBScript as an alternative from the beginning. Other browser vendors also provide or provided alternatives. Nevertheless, JavaScript is the preferred choice for making the web dynamic on the client's computer.
There are several reasons for this dominance. The most important reason is consistency. Every browser provides a JavaScript implementation. Even though there are some differences on the surface (API) and implementations, all implementations are at least ECMAScript 3 compatible. Here we have our common code basis that can be used to power browsers, which may run on variety of devices starting with computers over smartphones, tablets and TV sets.
It is this dominance that makes JavaScript interesting once a developer enters the web space. One might prefer static typing, but sometimes casting adds some noise that is just unwanted. One might prefer traditional classes and scopes, but the scripting nature is sometimes more straight forward and to the point. Any application that could be written in JavaScript, will be written in JavaScript.
Therefore just having an HTML parser in C# might be the basis of a great tool for some tasks, but it always excludes a huge fraction of code that is only available in JavaScript form. It is that fraction that we do not want to exclude. If there is already a great script that manipulates a webpage the way we want, why should we have to rewrite it?
AngleSharp has an extension point to include scripting engines. This may be used to register custom scripting languages (experimentally, or to have a great alternative), or to include official ones (such as VBScript or an ECMAScript implementation). Lucky for us, there are already some great scripting languages written in .NET:
- ScriptCS (and others), to make C# itself scriptable
- IPython (and other Python implementations)
- NeoLua (and other Lua implementations)
- Jurassic (JavaScript compiled to MSIL)
- JavaScript.NET (based on V8, a wrapper)
- Jint (JavaScript interpreter, presented as a PCL)
Of course there are many other languages. In this article we will use Jint to interpret ECMAScript (5) compatible code and apply DOM manipulations. Why Jint? The performance is certainly not as great as Jurassic (compiled) or JavaScript.NET (V8 is unbeatable, but the wrapper gives us a little penalty), however, it is strictly following the spec, available via NuGet (unlike JavaScript.NET) and PCL compatible. This does not exclude using the solution we discuss in this article on platforms such as WindowsPhone or Windows Store platforms.
Advancements in AngleSharp
The initial AngleSharp article discussed the principle behind DOM generation. Mainly the tokenization and parsing process have been viewed. There have not been any major changes besides some refinement and the addition of the HTML5 HTMLTemplateElement interface. The latter has been included in the parser as specified in the HTML 5.1 specification.
The main changes have been committed in the API and the CSS engine. While the API has been changed in such a way, that is flexible for users and following .NET coding standards, the CSS engine has been rewritten from scratch. It is now more flexible, easier to extend and faster.
We will first discuss the changes in the parsers, before we provide information on the configuration model implement in AngleSharp. Finally we will go into details of the currently provided DOM API and the available extension points.
HTML and CSS status
As already explained there are barely any changes to the HTML parser part. Nevertheless, some commits have been pushed and therefore we can expect some changes. Mostly further HTML DOM elements have been created, the API has been implemented and some performance improvements are available.
A quite important change, however, has been made to the API that is exposed. Instead of dealing with the implementation of the DOM elements, a standard user deals with the interface definition alone. This is like the W3C proposed and makes changes to the underlying implementation a lot easier. Here we have some kind of contract that is not very likely to break. Also the concrete implementation details are hidden. One thing to note is, that such an encapsulation is very important, since it allows refactoring of the implementation, without breaking user codes. It also allows to expose an API that is implement in a completely different way.
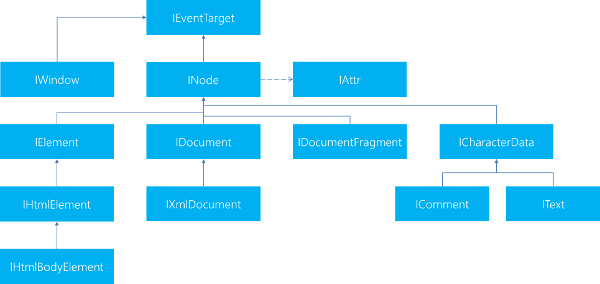
The following image showes a snippet of how the current HTML DOM tree looks like. The current version of AngleSharp implements the latest DOM (4). Therefore the EventTarget interface is on top. Additionally the Attr interface is not a Node. Finally the picture uses the prefixed notation as available in AngleSharp due to .NET convention.
One example of what is possible with AngleSharp is submitting HTML forms. Everyone who tried to wrap an existing website using C# knows the problem. There is no API and one needs to submit a form for receiving data. Leaving alone the data extraction problem, we need to inspect the form with all fields (text, hidden, ...), probably filling out some fields on the way. Most of the time one could not make a process as described work sufficiently good to use it in production. This is now over!
The HTMLFormElement contains the Submit() method, which will send the form's data to the specified action url. The method uses the current method (POST, GET, ...) and creates a request as specified officially. This makes the following scenario work: Get the contents of a login page, perform the login by submitting a form using user name and password, extract the data of a specific subpage and log out.
A really important piece for the described process is cookies. The session of the user must be saved in form of a (session) cookie. Additionally we require a unit to receive and send HTTP requests. Fortunately all three parts,
- Form submission
- Sending / receiving cookies
- Sending requests
are included in AngleSharp. Even though the last two points are only provided by default implementations and may be upgraded with better ones by any user.
A form submission can be as simple as follows (taken from the unit tests):
var url = "http://anglesharp.azurewebsites.net/PostUrlencodeNormal";
var config = new Configuration { AllowRequests = true };
var html = DocumentBuilder.Html(new Uri(url), config);
var form = html.Forms[0] as IHtmlFormElement;
var name = form.Elements["Name"] as IHtmlInputElement;
var number = form.Elements["Number"] as IHtmlInputElement;
var active = form.Elements["IsActive"] as IHtmlInputElement;
name.Value = "Test";
number.Value = "1";
active.IsChecked = true;
form.Submit();
In the recent versions the DOM model of AngleSharp has been updated to DOM4. Only a few methods and properties marked as obsolete are still being included. The only remaining ones are API artefacts that are heavily used by current websites. Also tree traversal has been updated by including helpers such as the NodeIterator, the TreeWalker and the Range class. These data structures make it possible to iterate through the DOM tree by filtering important nodes.
As usual the Document instance is used to create instances of such data structures. The idea is that the constructor with all the required data can be called from the Document without requiring the user of the API to know the exact signature of the specific class constructor. That also indicates the strong relation between the Document and e.g. the TreeWalker. The conclude the example the specific method is called CreateTreeWalker().
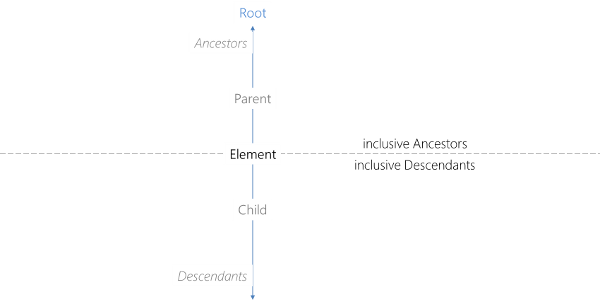
AngleSharp also contains methods that follow the official tree language. While the definitions for a parent or a child of an element are trivial, the specializations of ancestors and decendants are not. An inclusive ancestor is any ancestor of an element including the element. An inclusive descendant therefore is also the union of the element with the set of descendents. The root of an element is the top parent, i.e. the parent that does not have a parent.
Not only vertically there are such definitions, but also horizontally. Here we are interested in the width of the tree. From the perspective of a single element we will therefore have a look at its siblings. A sibling is every child of the parent of the current element, excluding the current element. We may differentiate between preceding and following siblings. While preceding siblings are found before the current element in tree order, following siblings come after the current element. In short: The index of preceding siblings is smaller than the index of the current element. Following siblings have an index that is greater than the index of the current element. The index is the position in the array of children of the parent.
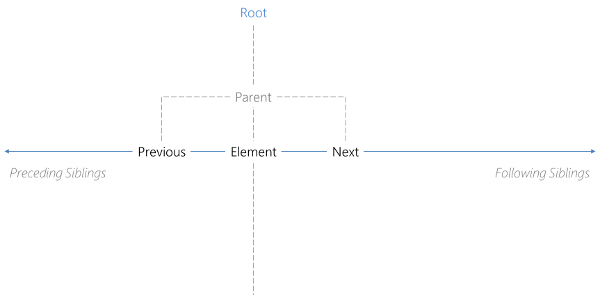
There are two special kinds of siblings: The previous (element) is the sibling with an index that is the nearest smaller index compared to the index of the current element. Similarly we have the next (element), which is the sibling with the closest higher index. For an index i of the current element we have i-1 for the previous element and i+1 for the next element. There may not be a previous or next element.
Finally a remark to the Range structure. The following diagram (taken from the official specification available at the W3C homepage) illustrates a few uses:
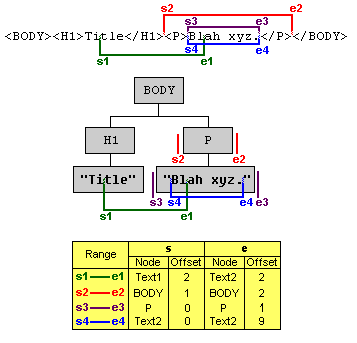
In the diagram we see four different ranges. the start of the range is called s#. The end is denoted by e#, where # is the number of the Range instance. For range 2, the start is in the body element. It is placed immediately after the h1 element and immediately before the paragraph tag. Therefore its position is between the h1 and p children of the document's body.
The offset of a boundary-point whose container is not a text node is
- 0 if it is before the first child,
- 1 if between the first and second child, and
- n if between the n-th and the (n+1)-th child.
So, for the start of range 2, the container is body and the offset is 1. The offset of a boundary-point whose container is a text node is obtained similarly. Here we use the number of (16-bit) characters for position information. For example, the boundary-point labelled s1 of range 1 has a Text node (the one containing "Title") as its container and an offset of 2 since it is between the second and third character.
We should note that the boundary-points of ranges 3 and 4 correspond to the same location in the text representation. An important feature of the Range class is that a boundary-point of a range can unambiguously represent every position within the document tree.
All iterators are live collections, i.e. they will change their representation according to changes in the DOM tree. The reason for this is quite simple: They do not have a fixed content, but retrieve their content upon request from the underlying DOM specified by the Document. The relation to the Document is therefore the minimum requirement for any structure that is live.
So what about CSS? The CSS API is now also nearly done. The last CSS version is CSS3, which builds directly upon CSS 2.1. However, CSS3 is also prepared for so-called modules. Everything is now in its own module. AngleSharp implements selectors module 4. There are other modules which are also implemented in their current state, an older state, or not at all. In general there are too many modules for implementing them in the core, or at all. Even current browsers do not implement all modules. Some of them are too special, some of them not in a production ready state and some of them are probably already outdated and have never been used widely.
What is most important is the declaration tree. When dealing with CSS we will eventually deal with a stylesheet that consists of CSS rules. These rules may nest. For instance a CSS media rule can nest other rules such as other media rules, normal styling rules or other document specific rules. A styling rule on the other side is probably the most important currency in CSS. It cannot nest other rules and consists of an element selector and a set of declarations.
Accessing this set of declarations is possible via the ICssStyleDeclaration interface. Each declaration is represented by a ICssProperty interface. A property is always split in multiple parts. We have the name of a property and its value. Historically there has been a way of accessing such values via the ICssValue interface. However, AngleSharp will most probably drop the support for this interface. It is very limited, not actively implemented and it will be removed by the W3C soon.
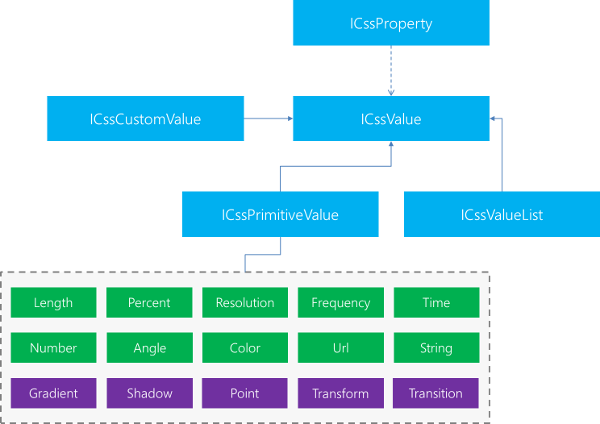
Therefore the tree, as shown in form of a snippet above, will change in further versions. In JavaScript (and probably also in C#) a regular user will set the value via a string. In C# there will also be the possibility of directly setting value, which happens to be the real deal. There won't be any clumsy abstraction that is very limited and just to unhandy to use in practice.
Configuration
Usually the process of parsing an HTML document involves construction of an instance of the HtmlParser class. However, the process may be confusing and too indirect for some users. Therefore a shorter way exists. We have the DocumentBuilder to shorten most parsing processes. The DocumentBuilder provides some static methods to directly create IDocument or ICssStyleSheet documents from different sources (string, Stream or Uri instances).
The problem is the variety of configuration that may be required for any process. For instance what kind (if any) requester (and for what kind of protocols, such as http or https) should be used? Are we providing a scripting engine or is scripting enabled at all? There are a lot of configuration options that could be set. Currently the precedence is as follows:
- A configuration has been supplied - take it.
- A custom configuration has been has been set as default - take it.
- Consider the default configuration.
A configuration is an object that implements IConfiguration. Depending on the specific needs one may create a class to implement IConfiguration from scratch, or based on Configuration, which contains a default implementation of the IConfiguration interface. Most of the times it will be sufficient just to instantiate the Configuration class and modify the content, without changing the implementation.
The default configuration can be set by calling the SetDefault() method of the Configuration class. By default an instance of the same class is the default configuration. This instance is practically immutable, since we cannot get the instance externally.
Let's have a look at what IConfiguration provides.
public interface IConfiguration
{
Boolean IsScripting { get; set; }
Boolean IsStyling { get; set; }
Boolean IsEmbedded { get; set; }
CultureInfo Culture { get; set; }
IEnumerable<IScriptEngine> ScriptEngines { get; }
IEnumerable<IStyleEngine> StyleEngines { get; }
IEnumerable<IService> Services { get; }
IEnumerable<IRequester> Requesters { get; }
void ReportError(ParseErrorEventArgs e);
}
We see that the configuration interface setups the context as we need it. We can specify if styling and scripting should be treated as active. This influences, e.g., how <noscript> tags will be treated. Additionally settings like the language, drawn from the Culture property, will be considered when picking the right encoding for the document.
Most notably we have two properties Services and Requesters that provide most of the magic behind extensions. While Services contain arbitrary services that are used for very special purposes, such as retrieving and storing cookies, Requesters contain all registeres stream requesters. There may be zero (just interested in parsing a single, provided document) or more requesters. The first requester that supports the protocol (scheme) of the current request is then considered.
Of course a major use case may be to retrieve a document (with sub-documents) from a network source that supports the HTTP protocol. Therefore a default requester (for the http and https protocol) has been supplied. Activing the default requester is quite easy.
var config = new Configuration().WithDefaultRequester();
The method WithDefaultRequester() is implemented as an extension method that requires an instance of Configuration or specialized. It returns the provided instance to support chaining. We are allowed to write expressions such as:
var config = new Configuration()
.WithDefaultRequester()
.WithCss()
.WithScripting();
The former expression creates a new AngleSharp configuration instance with the default http / https requester, the CSS styling engine registered and being active, and scripting being active. Note: No scripting engine has been added in the line. Even though we active scripting, we did not supply a (JavaScript) scripting engine and will therefore not be able to run any scripts. Nevertheless, the <noscript> tag will be treated as containing a block of raw text, i.e. as being ignored in the DOM generation.
The DOM API
One of the critics about the AngleSharp project is the usage of the official W3C DOM API. In my opinion, however, it is much better to start with the original API and add sugar on top of it. The reasons are many fold:
- It is much easier to connect script engines to it, which allow running scripts that already access the original API.
- A lot of documentation for the official API exists.
- Standards drive the web, we should first be fully standard conform before adding our own thing.
- Extensions (see jQuery) can be created on top of it, which provide a much better API.
Right now the basic (official) API is nearly finished. The implementation of some methods is still behind, but will be complete in the next couple of months. Most improvements and shortcuts will be implemented by using extension methods. This will not collide with the existing API, make the right indication and also ensure that everything is build on the official API (which should be the common base - just to ensure validity).
The API shifted to DOM L4. Only a few artefacts from former DOM specifications are still included. Most of those artefacts come from heavy usage on various webpages. If an API method or property still seems to be in heavy use, but was excluded in DOM L4, we still included it in AngleSharp (most likely).
Extension points
AngleSharp lives from its ability to be extended. Extensions are only useful, because AngleSharp knows how to integrate them. They are called in certain scenarios. Let's consider the case we want to investigate in this article. Here we are interested in integrating a scripting engine.
What has to be done? On finding a certain kind of <script> tag we want AngleSharp to look for a script engine that matches the given scripting language. The scripting language is usually set in form of an attribute. If there is no attribute for the scripting language, JavaScript is taken automatically. In this case we have "text/javascript". If an engine with the given type is registered, we need to run a method for evaluating the script.
This is where it becomes tricky. A script might either be delivered inline (just a string), or in form of an external resource. If the latter is true, then AngleSharp will automatically perform the request (if possible). In this scenario the source is presented in form of a response, which contains the content as a stream, the header and additional information about the response, such as the URL.
The following defines a script engine.
public interface IScriptEngine
{
String Type { get; }
void Evaluate(String source, ScriptOptions options);
void Evaluate(IResponse response, ScriptOptions options);
}
There are other examples that follow this pattern. The following snippet shows the interface for registering a style engine. Even though CSS3 is already included in AngleSharp, we might consider replacing it with our own implementation, or another engine (such as the ported one from Mozilla Firefox). We could also consider registering a styling engine for other formats, such as XML, LESS or SASS. The latter two could be preprocessed and transformed using the original CSS3 engine.
public interface IStyleEngine
{
String Type { get; }
IStyleSheet Parse(String source, StyleOptions options);
IStyleSheet Parse(IResponse response, StyleOptions options);
}
Having these interfaces on board makes AngleSharp quite flexible. It also gives AngleSharp the ability to expose functionality that is not included out-of-the-box. Sometimes this is due to the focus of the project, sometimes this is due to platform constraints. Whatever the reasons are, being easily extensible is certainly a bonus. Before we go on we should note, that AngleSharp is still in beta, which is why the API (including the interfaces for extensions) is still in flux. For information on the latest version, please consult the official repository hosted at GitHub.
Another example is the the ICookieService interface. This interface also uses the IService interface, which marks general services. Services are just AngleSharps way to declare a huge variety of extensions, which are not directly vital for any functions, but may bring in new connections, possibilities or gather information. The ICookieService has its purpose to provide a common store for cookies. Additionally information about a cookie, for instance if the cookie is http-only, has to be read and evaluated.
public interface ICookieService : IService
{
String this[String origin] { get; set; }
}
We see that the service defines a getter and setter property, for a given origin string. Cookies are always considered for a particular "domain", called origin. This consists of the complete host and protocol part of the url. The cookie service is used when the cookie has to be read from a response, has been changed in the DOM or is required for sending a request.
Connecting Jint
Connecting a JavaScript engine to AngleSharp using the IScriptEngine interface can be either very easy or very challenging. The main issue is the connection between .NET objects and the engine's expected form. Usually we will be required to write wrappers, which follow the basic structure dictated by the specified engine.
Additionally we might want to rename some of the .NET class and method (including property) names. Events, constructors and indexers also may require additional attention from our side. Nevertheless, with reflection on our side we can write such a wrapper generator without spending much time.
In the following we will first glance at Jint. After having uerstndood the main purpose and inner workings of Jint we will move on to automatically wrap the incoming objects as scriptable objects. The outgoing objects have to be unwraped as well, however, this part is then trivial as we will see.
Understanding Jint
Jint is a .NET implementation of the EcmaScript 5 specification. It therefore contains (almost) everything that has been specified officially. However, that does not mean that everything works as one expects in a browsers. Most parts of the JS API in the browser come from the DOM / W3C. For instance the XmlHttpRequester for making requests from JavaScript.
JavaScript focuses on key-value pairs, where keys are strings. The values in Jint are represented as JsValue instances. However, we can be more general and register functions for retrieving the specific value. A function is not confuse with a JavaScript function. That is a kind of value. Why would we want to use functions instead of values? This is how properties work in C#. A property is nothing but a function, that is called like a variable. We want to expose that same behavior in JavaScript, otherwise we would be required to read out every value when we touch the parent object.
Reading out every value once we touch the parent object is not only a performance problem. It also implies that we would be required to update the parent object. In general this is not what we want. We want the parent to appear "live" without being forced to manually update all the (JavaScript) properties. Therefore obtaining the same behavior as in C# is indeed desired and may reduce some unintentional side-effects, that may come when exposing an API with a wrapper.
The first thing we need to do when connecting a JavaScript engine is to create a class that implements the IScriptEngine interface. In the end we need to register an instance of our engine in the configuration we supply to AngleSharp.
It is important to set the correct type for the new scripting engine. The type corresponds to the mime-type of the supplied script. At the moment it is unclear if the Type property will remain in the interface, or if it will be replaced by a method, that checks if a provided type matches the types covered by the scripting engine. The latter is in general harder to implement, however, more flexible. It could match several (or any, or none) types.
Let's see how the implementation looks in this case:
public class JavaScriptEngine : IScriptEngine
{
readonly Engine _engine;
readonly LexicalEnvironment _variable;
public JavaScriptEngine()
{
_engine = new Engine();
_engine.SetValue("console", new ConsoleInstance(_engine));
_variable = LexicalEnvironment.NewObjectEnvironment(_engine, _engine.Global, null, false);
}
public String Type
{
get { return "text/javascript"; }
}
public void Evaluate(String source, ScriptOptions options)
{
var context = new DomNodeInstance(_engine, options.Context ?? new AnalysisWindow(options.Document));
var env = LexicalEnvironment.NewObjectEnvironment(_engine, context, _engine.ExecutionContext.LexicalEnvironment, true);
_engine.EnterExecutionContext(env, _variable, context);
_engine.Execute(source);
_engine.LeaveExecutionContext();
}
public void Evaluate(IResponse response, ScriptOptions options)
{
var reader = new StreamReader(response.Content, options.Encoding ?? Encoding.UTF8, true);
var content = reader.ReadToEnd();
reader.Close();
Evaluate(content, options);
}
}
Creating the engine requires us to provide the usual stuff that can be found in all popular implementations (any browser, node, ...). An example would be the console object. In this sample we only supply the most important methods, such as log() for piping an arbitrary number of objects to the console output.
What else is there to say? First of all the two Evaluate() methods do not really differ much. The one that takes a Stream as input just reads the whole Stream into a String. Normally we would prefer a Stream, however, Jint just takes a String as source.
Nevertheless, what is important is that Jint supports executions contexts. This allows us to place a custom execution context just for the provided evaluation. After the script is finished, we will leave the execution context. The object to host the execution context is the Window object supplied by the scripting options.
In JavaScript the context is everything. But the context is a very relative concept. In fact, while the context with its parents determines the variable resolution, it also determines the associated this pointer. The global context is the one layer that cannot be left. Whatever we do, we will always end up in the global context.
Our global context in DOM manipulation is actually two-fold. On the one hand we have the JavaScript API with objects such as Math, JSON and the original type objects (String, Number, Object and others). On the other hand we also have a DOM layer that maps the IWindow object. Therefore the naming resolution will directly resolve IWindow based properties. Nevertheless, this "JavaScript" object, which represents the IWindow ".NET" object, can also be extended. Therefore it will also act as the this, which is extended with properties if no available property is found.
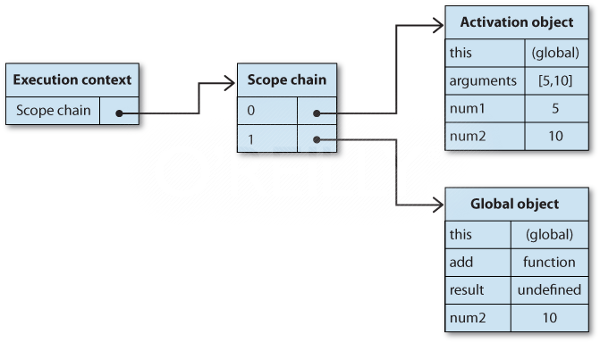
Other contexts can be placed on top of this. Jint allows the manual placement of an execution context, which makes wrapping objects such as the IWindow instance possible. Without it, we cannot distinguish between our global object and the global JavaScript API.
Another thing that is essential (and perfectly done right by Jint) is the representation of the JavaScript prototype pattern. Every object has a prototype. The instantiation of any object results in an object with a prototype. That may sound weird at first, but this detailled picture will help:
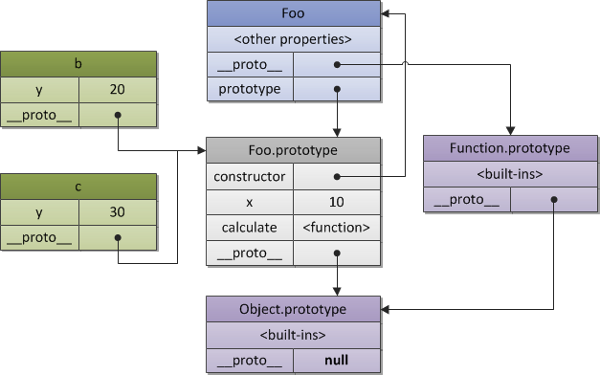
In ES5 we have two properties. One is called prototype and the other is called __proto__. If we have a classic constructor function, such as function Foo() { /* ... */ } we have obviously something from type Function. Therefore the __proto__ property maps to the Function object. Nevertheless, once we create an instance of Foo, we have an Object. Therefore, at least in the beginning, the prototype of Foo maps to Object. So the prototype of a constructor function becomes the __proto__ of an instance created by the constructor function.
We can go on in this chain, but the only thing to note at this point is that Jint does everything right. Our part consists only of deriving from the respective object, such as ObjectInstance. By doing so, we set the __proto__ property of the resulting instance. That's all!
Automating wrappers
As we have seen, one thing we actually need to do is creating wrappers or unwrapping objects from our wrappers. In order to generate wrapper objects on the fly a simple mechanism has been developed. Nevertheless, a much harder thing than just wrapping (DOM) objects to (JS) Jint objects is wrapping functions (delegates).
Here we need to apply some reflection magic. Additionally we need to consider some properties of the FunctionInstance class that is provided by Jint. The following code shows two things:
- Wrapping a function instance to an arbitrary delegate
- Wrapping a function instance to a
DomEventHandler
There is a shortcut if the specific target is not known. By calling the ToDelegate method we will always get the right choice.
static class DomDelegates
{
public static Delegate ToDelegate(this Type type, FunctionInstance function)
{
if (type == typeof(EventListener))
return ToListener(function);
var method = typeof(DomDelegates).GetMethod("ToCallback").MakeGenericMethod(type);
return method.Invoke(null, new Object[] { function }) as Delegate;
}
public static DomEventHandler ToListener(this FunctionInstance function)
{
return (obj, ev) =>
{
var engine = function.Engine;
function.Call(obj.ToJsValue(engine), new[] { ev.ToJsValue(engine) });
};
}
public static T ToCallback<T>(this FunctionInstance function)
{
var type = typeof(T);
var methodInfo = type.GetMethod("Invoke");
var convert = typeof(Extensions).GetMethod("ToJsValue");
var mps = methodInfo.GetParameters();
var parameters = new ParameterExpression[mps.Length];
for (var i = 0; i < mps.Length; i++)
parameters[i] = Expression.Parameter(mps[i].ParameterType, mps[i].Name);
var obj = Expression.Constant(function);
var engine = Expression.Property(obj, "Engine");
var call = Expression.Call(obj, "Call", new Type[0], new Expression[]
{
Expression.Call(convert, parameters[0], engine),
Expression.NewArrayInit(typeof(JsValue), parameters.Skip(1).Select(m => Expression.Call(convert, m, engine)).ToArray())
});
return Expression.Lambda<T>(call, parameters).Compile();
}
}
The first two parts are quite obvious, but the third method is where real work has to be applied. Here we are basically constructing a delegate of type T, which wraps the passed FunctionInstance instance. The problem that is solved by the method is wrapping the parameter by passing on the required existing parameters. Nevertheless, the problem with this approach comes from JavaScripts dynamic nature. We have to live with the possibility of leaving out parameters. The question is: Are the parameters that have been left out optional? What if we find too many arguments? Should be drop the additional ones, or is a params parameter the reason for this? If the latter is the case, we actually need to construct an array.
There are more questions, but the most important ones are addressed by the implementation shown above. Finally, we compile an Expression instance, which is quite a heavy process, but unfortunately required for the shown process. One could (and should) buffer the result to speed up further usages, but this is not required for our little example.
So let's have a look at our standard (DOM) object wrapper. The following class is basically all that's required for connecting AngleSharp to Jint. Of course there is more than meets the eye, but most of the other classes and methods deal with special cases like the one above, where we wrapped delegates. Similar cases involve indexers, events and more.
sealed class DomNodeInstance : ObjectInstance
{
readonly Object _value;
public DomNodeInstance(Engine engine, Object value)
: base(engine)
{
_value = value;
SetMembers(value.GetType());
}
void SetMembers(Type type)
{
if (type.GetCustomAttribute<DomNameAttribute>() == null)
{
foreach (var contract in type.GetInterfaces())
SetMembers(contract);
}
else
{
SetProperties(type.GetProperties());
SetMethods(type.GetMethods());
}
}
void SetProperties(PropertyInfo[] properties)
{
foreach (var property in properties)
{
var names = property.GetCustomAttributes<DomNameAttribute>();
foreach (var name in names.Select(m => m.OfficialName))
{
FastSetProperty(name, new PropertyDescriptor(
new DomFunctionInstance(this, property.GetMethod),
new DomFunctionInstance(this, property.SetMethod), false, false));
}
}
}
void SetMethods(MethodInfo[] methods)
{
foreach (var method in methods)
{
var names = method.GetCustomAttributes<DomNameAttribute>();
foreach (var name in names.Select(m => m.OfficialName))
FastAddProperty(name, new DomFunctionInstance(this, method), false, false, false);
}
}
public Object Value
{
get { return _value; }
}
}
Alright, quite some code dump, but the important step is to call the SetMembers() method with the type information of the current value, i.e. value.GetType(). The SetMembers() method itself is responsible for obtaining the right (DOM) interface or populating triggering the population of properties and methods if a DOM interface has been found.
Finally we start adding the methods that are contained in the interface. As name we choose the value stored in the DomNameAttribute attribute. Similarly we also include all properties listed in the interface, also with the right name.
How does the DomFunctionInstance look like? The key is to provide a new implementation for the Call() method. Here we actually perform some magic.
The main issue is unwrapping the arguments into the usual structure. We already discussed the problem briefly. Now we want to look on how these arguments are being processed. The BuildArgs() method is responsible for this magic.
sealed class DomFunctionInstance : FunctionInstance
{
readonly MethodInfo _method;
readonly DomNodeInstance _host;
public DomFunctionInstance(DomNodeInstance host, MethodInfo method)
: base(host.Engine, GetParameters(method), null, false)
{
_host = host;
_method = method;
}
public override JsValue Call(JsValue thisObject, JsValue[] arguments)
{
if (_method != null && thisObject.Type == Types.Object)
{
var node = thisObject.AsObject() as DomNodeInstance;
if (node != null)
return _method.Invoke(node.Value, BuildArgs(arguments)).ToJsValue(Engine);
}
return JsValue.Undefined;
}
Object[] BuildArgs(JsValue[] arguments)
{
var parameters = _method.GetParameters();
var max = parameters.Length;
var args = new Object[max];
if (max > 0 && parameters[max - 1].GetCustomAttribute<ParamArrayAttribute>() != null)
max--;
var n = Math.Min(arguments.Length, max);
for (int i = 0; i < n; i++)
args[i] = arguments[i].FromJsValue().As(parameters[i].ParameterType);
for (int i = n; i < max; i++)
args[i] = parameters[i].IsOptional ? parameters[i].DefaultValue : parameters[i].ParameterType.GetDefaultValue();
if (max != parameters.Length)
{
var array = Array.CreateInstance(parameters[max].ParameterType.GetElementType(), Math.Max(0, arguments.Length - max));
for (int i = max; i < arguments.Length; i++)
array.SetValue(arguments[i].FromJsValue(), i - max);
args[max] = array;
}
return args;
}
static String[] GetParameters(MethodInfo method)
{
if (method == null)
return new String[0];
return method.GetParameters().Select(m => m.Name).ToArray();
}
}
What are we doing here? We provide some checks that the incoming arguments are sane. Then we construct an array called args, which is basically the set of parameters that needs to be processed. Finally, after including a variety of possibilities such as optional types, variadic input, we return the converted and packaged arguments in the proper format, as an array of objects.
Using the code
I extracted the scripting project in form of a sample WPF JS DOM REPL (a WPF JavaScript Document Object Model Read-Evaluate-Print-Loop) application. Hence this is basically a JavaScript console as known from almost every browser. The provided source code is frozen and won't be updated.
Instead the current source (from this small project, as well as AngleSharp and related projects) can be found on the project's page, hosted at GitHub. The project can be reached at github.com/FlorianRappl/AngleSharp.
If you find extreme bugs to the sample, then consider posting here. If small bugs in the application are found, or any bug in AngleSharp itself, then please prefer the issues page at GitHub. Also if you are in doubt where to post anything related to the project, consider the issues page at GitHub.
So in short: Article related (typos, bugs in the sample, praise [hopefully!], ...) comments should be posted here, all other topics are discussed on GitHub. Personally, I will never ignore them, however, it makes things simpler and easier to follow for everyone if the discussion is centralized and focused.
Points of Interest
AngleSharp is not the only HTML parser written entirely in C#. In fact AngleSharp has quite a tough competition to fight against. There are reasons to choose some other parser for doing the job, however, in general AngleSharp might be more than okay for the job. If in doubt, then choose AngleSharp. If we want to create a headless browser, then AngleSharp is certainly the tool for the job.
One might argue that other options for controlling a headless browser exist. That is certainly true, but most of these tools build on libraries that have been written in another language which do not compile to .NET code. Therefore these libraries are just wrappers, which may have drawbacks in the areas of performance or agility. Also robustness may be an issue.
History
- v1.0.0 | Initial Release | 07.11.2014